
Speech and music are human universals, and people around the world often blend them into vocal songs. This entwinement of the speech and music cognitive domains is a challenge for the auditory cognitive system. How do listeners extract words and melodies from a single sound wave?
Speech and musical sounds are thought to differ in details of their acoustic structure and thus activate different receptive preferences of the left and right auditory cortices of the brain.
Now, a new study by McGill University has used a unique approach to reveal why this specialization exists.
Scientists created 100 a capella recordings, each of a soprano singing a sentence. They then distorted the recordings along two fundamental auditory dimensions: spectral and temporal dynamics and had 49 participants distinguish the words or the words of every tune. The test was led in two groups of English and French speakers to enhance reproducibility and generalizability.
For both languages, when the temporal information was distorted, participants seemed to have trouble distinguishing the speech content, but not the melody. In contrast, when spectral information was changed, they had difficulty identifying the melody, but not the speech. It suggests- speech and melody depend on different acoustical features.
Scientists later tested the way the brain responds to different sound features. For this, they scanned the participant’s brain using fMRI while they distinguished the sounds. They found that speech processing occurred in the left auditory cortex, while melodic processing happened in the right auditory cortex.
Scientists next set out to determine how degradation in each acoustic dimension would affect brain activity. They found that degradation of the spectral dimension only influenced activity in the right auditory cortex, and only during melody perception. In contrast, degradation of the temporal dimension affected only the left auditory cortex, and just during speech perception. This shows the differential response in each hemisphere type relies upon the kind of acoustical data in the stimulus.
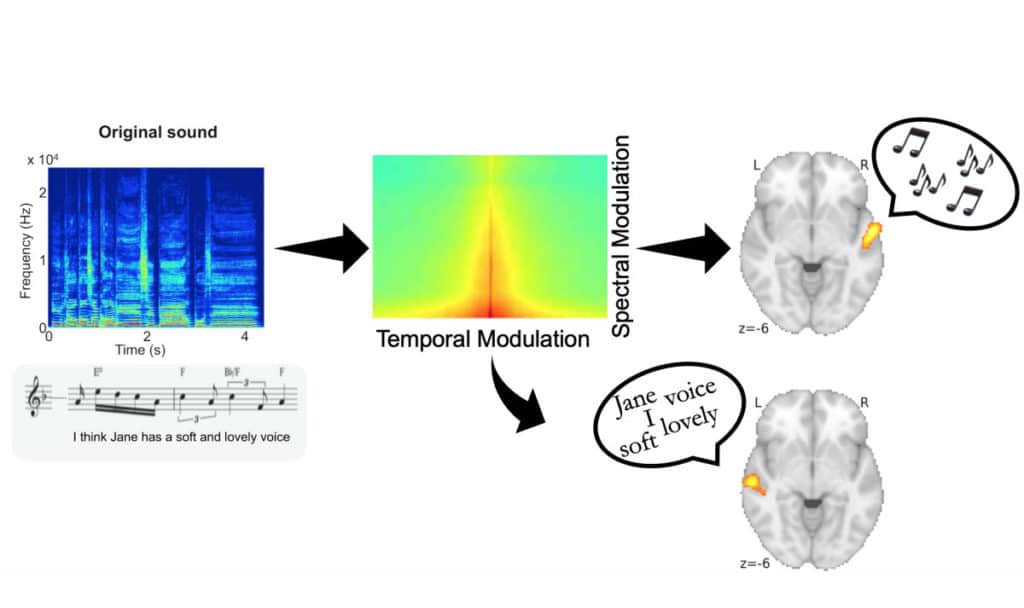
This study shows that music and speech exploit different ends of the spectro-temporal continuum and that hemispheric specialization may be the nervous system’s way of optimizing the processing of these two communication methods.
Philippe Albouy, the study’s first author, said, “It has been known for decades that the two hemispheres respond to speech and music differently, but the physiological basis for this difference remained a mystery. Here we show that this hemispheric specialization is linked to basic acoustical features that are relevant for speech and music, thus tying the finding to basic knowledge of the neural organization.”
Their results were published in the journal Science on Feb. 28, 2020.