
Quantum computers aren’t constrained to two states; they encode data as quantum bits, or qubits, which can exist in superposition. Qubits represent, particles, photons or electrons, and their respective control devices that are working together to act as computer memory and a processor.
Qubits can interact with anything nearby that carries energy close to their own, for example, photons, phonons, or quantum defects, which can change the state of the qubits themselves.
Manipulating and controlling out qubits is performed through old-style controls: pure signal as electromagnetic fields coupled to a physical substrate in which the qubit is implanted, e.g., superconducting circuits. Defects in these control electronics, from external sources of radiation, and variances in digital-to-analog converters, introduce even more stochastic errors that degrade the performance of quantum circuits. These practical issues impact the fidelity of the computation and thus limit the applications of near-term quantum devices.
Emerging reinforcement learning techniques using deep neural networks have shown great promise in control optimization. They harness non-local regularities of noisy control trajectories and facilitate transfer learning between tasks.
To improve the computational capacity of quantum computers, and to pave the road towards large-scale quantum computation, Google scientists have created a new quantum control framework called UFO. For this, scientists used deep reinforcement learning, where a single control cost function can encapsulate various practical concerns in quantum control optimization.
The framework provides fast and high-fidelity quantum gate-control optimization by reducing average quantum logic gate error of up to two orders-of-magnitude over standard stochastic gradient descent solutions and a significant decrease in gate time from optimal gate synthesis counterparts.
The novelty of this new quantum control paradigm pivots upon the development of a quantum control function and a proficient advancement technique dependent on deep reinforcement learning.
To devise an overall cost function, scientists primarily need to develop a physical model for the realistic quantum control process, one where they can reliably predict the amount of error.
One of the most detrimental errors to the accuracy of quantum computation is leakage: the amount of quantum information lost during the calculation. Such information leakage usually happens when the quantum state of a qubit gets eager to a higher energy state or decays to a lower energy state through unconstrained emanation. Leakage errors do not just lose valuable quantum data; they likewise corrupt the “quantumness” and in the end, diminish the performance of a quantum computer to that of classical.
Simulating the whole computation is a common practice used to precisely evaluate the leaked information. Though, he defeats the purpose of building large-scale quantum computers, since their advantage is that they can perform calculations infeasible for classical systems.
This work opens up a new direction for quantum analog-control optimization using RL, where random control errors and incomplete physical models of environmental interactions are taken into account during the control optimization. On-policy RL is well known for its ability to leverage non-local features in control trajectories, which becomes crucial when the control landscape is high-dimensional and packed with a combinatorially large number of non-global solutions, as is often the case for quantum systems.
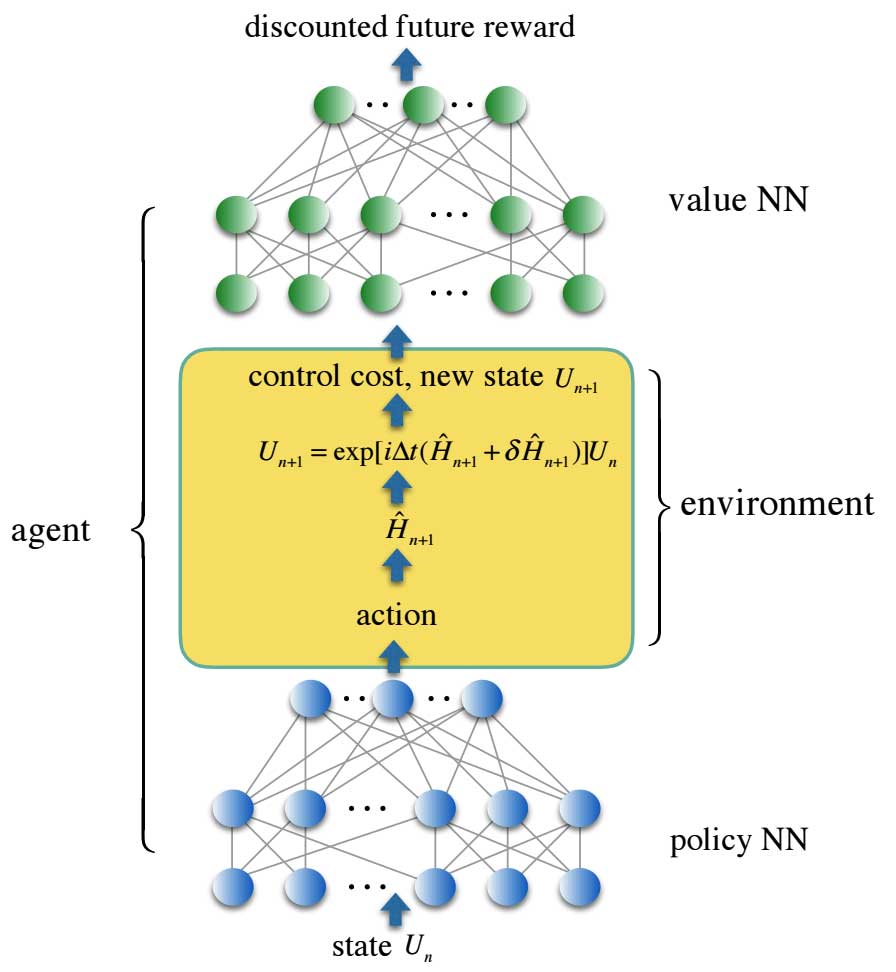
Scientists then encoded the control trajectory into a three-layer: Fully connected neural network- the policy neural network and the cost control cost function into a second NN—the value NN—which encodes the discounted future reward.
Robust control solutions were obtained by fortification learning agents, which trains both neural networks under a stochastic situation that mimics a realistic noisy control actuation. We provide control solutions to a set of continuously parameterized two-qubit quantum gates that are important for quantum chemistry applications but are costly to implement using the standard universal gate set.
Scientists noted, “Under this new framework, our numerical simulations show a 100x reduction in quantum gate errors and reduced gate times for a family of continuously parameterized simulation gates by an average of one order-of-magnitude over traditional approaches using a universal gate set.”
“This work highlights the importance of using novel machine learning techniques and near-term quantum algorithms that leverage the flexibility and additional computational capacity of a universal quantum control scheme. More experiments are needed to integrate machine learning techniques, such as the one developed in this work, into practical quantum computation procedures to fully improve its computational capacity through machine learning.”
The work is published in Nature Partner Journal (npj) Quantum Information.