
What would you feel if you heard yourself speaking another language that you hardly know? Well, it is something that Google wants to make possible in reality. Google has introduced a first of its kind translation model that could make speaking another language easier!
The company announced its first direct speech-to-speech translation system called “Translatotron” that can directly convert speech from one language into another while maintaining a speaker’s voice and cadence.
Translatotron is based on a sequence-to-sequence network that takes source spectrograms- a visual representation of the spectrum of frequencies- as input. Then it generates the spectrograms of the translated content in the target language.
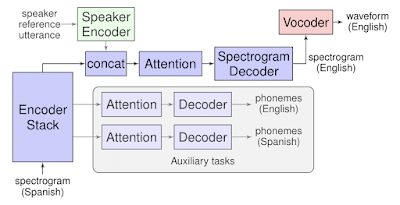
Most translation system splits the job into three parts. First one turns the speech into text, the next one takes that text and translates it into another language, and the third one turns the text back to the speech. Also, it happens often in a different voice from the original speaker.
Whereas, the company’s new system avoids dividing the task into separate stages. It provides a few advantages over cascaded systems, including faster inference speed, naturally avoiding compounding errors between recognition and translation, making it straightforward to retain the voice of the original speaker after translation, and better handling of words that do not need to be translated, Ye Jia and Ron Weiss, Software Engineers explained in google blog.
Also, the tool makes use of two other separately trained components. The first one is a neural vocoder that converts output spectrograms to time-domain waveforms. While the second one is an optional speaker encoder component, which works to maintain a speaker’s voice in the synthesized translated speech.
Google’s AI researchers believe that an end-to-end system can make the task easier by removing the middle man, where the speech is translated into text first. Further research in this field could prove to be fruitful for Google’s future AI-powered translation systems.