Even the most advanced chatbots can’t hold a decent conversation, but AI systems are getting better at generating the written word. But how to detect AI-generated text?
That question led the Harvard scientists to develop a statistical method, along with an open-access interactive tool, to differentiate language generated by code from human speech.
Normal language generators are prepared on tens of millions of online texts and mimic human language by predicting the words that frequently follow each other. For instance, the words “have,” “am,” and “was” are statically destined to come after “I.”
Utilizing that thought, scientists built up a strategy that, rather than hailing mistakes in content, recognizes excessively predictable content.
Sebastian Gehrmann, a Ph.D. candidate at the Graduate School of Arts and Sciences said, “The idea we had is that as models get better and better, they go from definitely worse than humans, which is detectable, to as good as or better than humans, which may be hard to detect with conventional approaches.”
Hendrik Strobelt, a researcher at IBM, said, “Before, you could tell by all the mistakes that text was machine-generated. Now, it’s no longer the mistakes but rather the use of highly probable (and somewhat boring) words that call out machine-generated text. With this tool, humans and AI can work together to detect fake text.”
Scientists dubbed this method as GLTR. The tool inspects the visual footprint of an automatically generated text. It enables a forensic analysis of how likely an automatic system made a text.
The method is based on a model trained on 45 million texts from websites — the free version of the OpenAI model, GPT-2 because it uses GPT-2 to detect generated text.
Working:
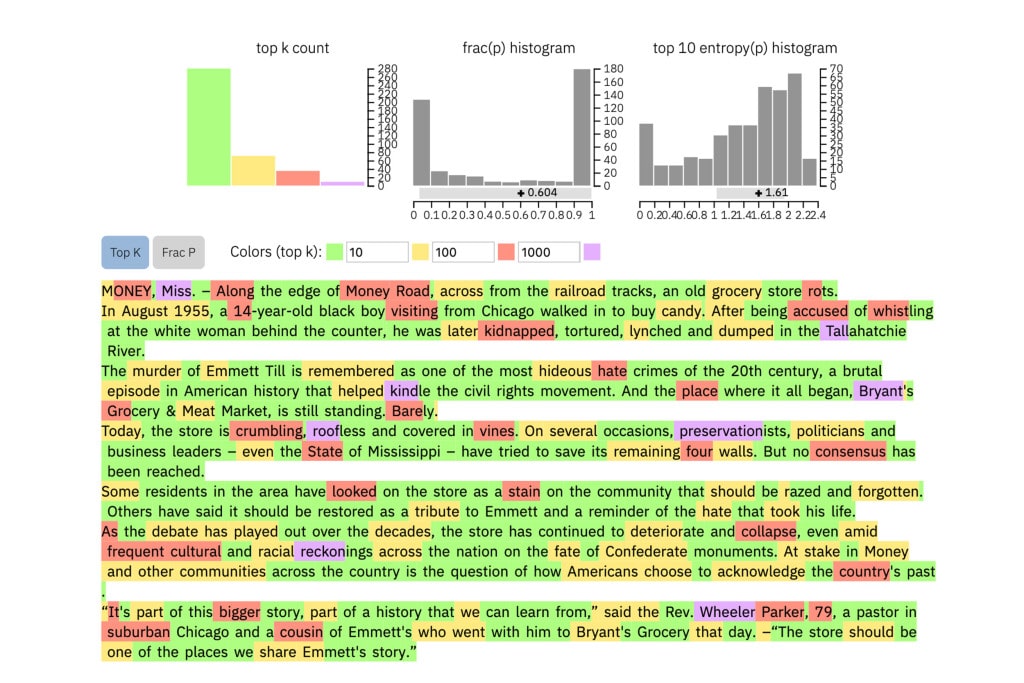
When a user enters a text, the method highlights each word in green, yellow, red, or purple. Green indicates predictable word; Yellow indicates moderately predictable word, red shows not very predictable, and purple means the model wouldn’t have predicted the word at all.
Scientists tested the model with a group of undergraduates in a SEAS computer science class. Without the model, the students could identify about 50 percent of AI-generated text. With the color overlay, they identified 72 percent.
Gehrmann said, “Our goal is to create human and AI collaboration systems. This research is targeted at giving humans more information so that they can make an informed decision about what’s real and what’s fake.”
A paragraph of text generated by GPT-2 will look like this:
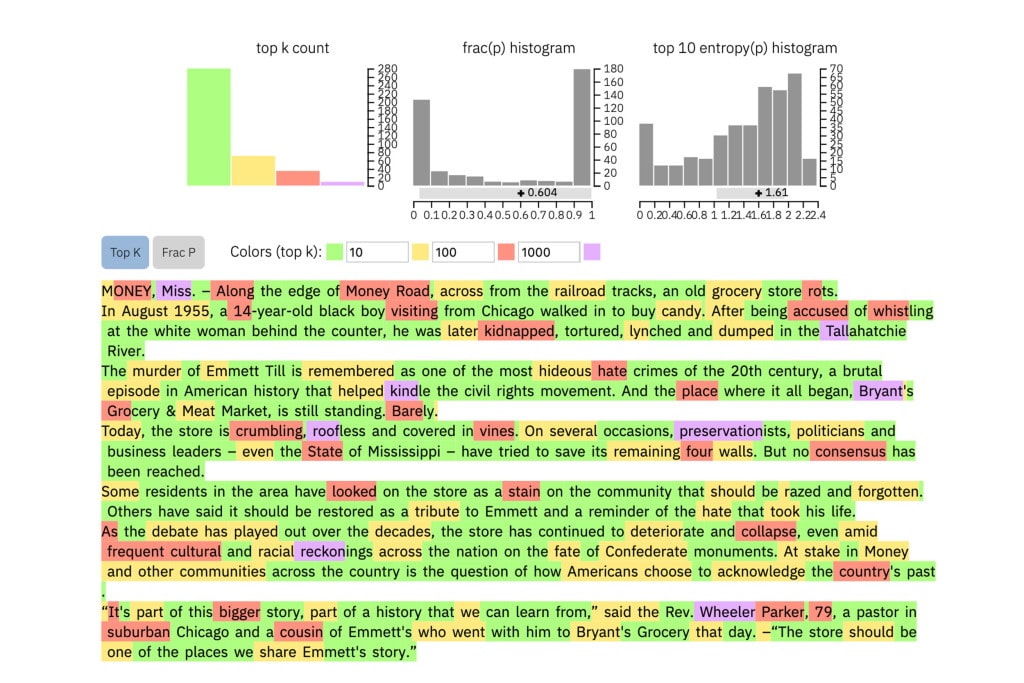
To compare, this is a real New York Times article: