
It has now become old news that DeepMind’s AI has become masters at video games. After developing an AI system that can beat Chess and Go, now the Google-owned DeepMind started tackling a different class of games. The AI has now figured out how to master co-operative multiplayer games as well which usually requires teamwork.
A team of programmers at a British artificial intelligence company has designed automated “agents” that taught themselves how to play a competitive first-person multiplayer video game shooter, and became so good that they were able to outperform human teammates – and with the reaction time slowed down to that of a typical human player.
For the study, the team worked on a modified version of Quake III Arena, a seminal shooter that was first released in 1999. They chose the ‘Capture the Flag’ game mode that requires each of two teams to capture as many of the other teams’ flags as possible.
The teams begin at base camps set at opposite ends of a map, which is generated at random before each round. Players roam about, interacting with buildings, trees, hallways, and other features on the map, as well as with allies and opponents. They try to use their laser-like weapons to “tag” members of the opposing team; a tagged player must drop any flag he might have been carrying on the spot and return to his team’s base.
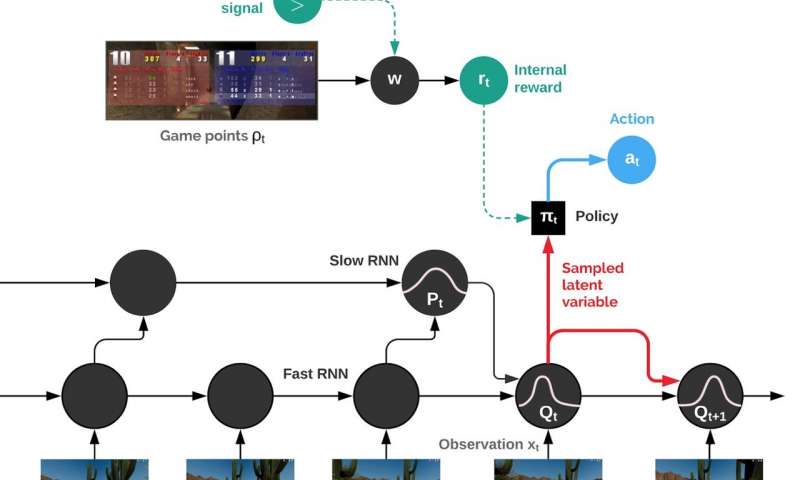
DeepMind represents each player with a software agent that sees the same screen a human player would see. The agents have no way of knowing what other agents are seeing; again, this is a much closer approximation of real strategic contests than most board games provide.
The DeepMind AI taught itself the skill through a technique called reinforcement learning. Essentially, it picked up the rules of the game over thousands of matches in randomly generated environments. The result is to combine the behavior of the agent in a purposeful manner, which is called “policy”. Each agent develops its policy on its own, which means it can specialize a bit.
But, there is a limit. After every 1000 iterations of the game, the system compares policies and predicts how well the whole team would do if it were to imitate this or that agent. If any agent’s winning chances turn to be less than 70% as high as another’s, then the weaker agent copies the stronger one.
Agents start out as blank slates, but they do have one feature built into their way of evaluating things. It’s called a multi-time scale recurrent neural network with external memory, and it keeps an eye not only on the score at the end of the game but also at earlier points. The researchers note that “Reward purely based on game outcome, such as win/draw/loss signal…is very sparse and delayed, resulting in no learning. Hence, we obtain more frequent rewards by considering the game points stream.”
This program can beat the human players when starting from a randomly generated position. Even after 12 hours of practice, the human game testers were only able to win 25% of games against the agent team, drawing 6 percent of the time, and losing the rest.
However, when two professional game testers were given a particularly complex map that had not been used in training and was allowed to play games on that map against two software agents, the pros needed just 6 hours of training to come out on top.
The work of the researchers from DeepMind, which is owned by Google’s parent company Alphabet, was described in a paper published in Science on Thursday and marks the first time the feat has ever been accomplished.
Also, the team is hoping that training an AI to play multiplayer successfully could help in training other similar AI systems in the real world, such as helping human employees inside massive distribution centers.
Journal Reference
- Morcos, Avraham Ruderman, Nicolas Sonnerat, Tim Green, Louise Deason, Joel Z. Leibo, David Silver, Demis Hassabis, Koray Kavukcuoglu and Thore Graepel; Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science Vol 364, Issue 6443 pp. 859-865 DOI: 10.1126/science.aau6249